Choisissez le fuseau horaire
Le fuseau horaire de votre profil:
The first two days will be organised in 4 sessions:

The three thematic days will have each two sessions:
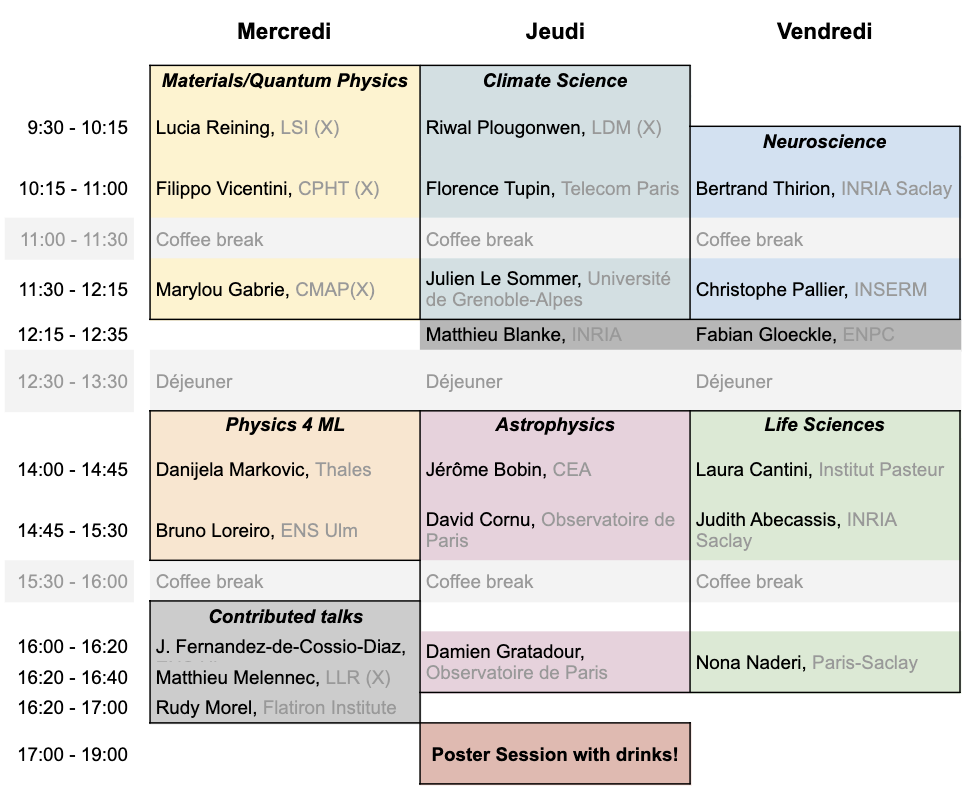
Titles and abstracts are available in the detailed Timetable or in the Contribution List.
The goal of Sacl-AI for Science Workshop is to gather faculy, researchers and students who work, would like to work or are interested in applications of machine learning to science.
It is an opportunity for novices to be introduced to some foundational topics in machine learning with a clear aim at solving problems in sciences, and for researchers to present their work and network with the wider community working on AI4Science in Saclay and surroundings.
The intent of the event is both to widen the community and to increase discussions between different actors and institutions.
The event is structured as follows:
- Day 1&2: A School on foundational ideas in ML for scientists coming from different scientific disciplines. The aim is to communicate effectively how several tasks comonly faced by researchers can be solved effectively and to high accuracy with those tools, giving concrete examples in different domains (Physics, Experiments, Math, Biology, Data analysis...) and discussing practical examples in coding sessions in order to empower attendees to use those techniques themselves in their research.
Certificates for PhD students will be given upon request to validate as a training session.
- Day 3, 4 & 5: Deep dive thematic days on Machine Learning applications to different fields. Every day will be centered on a broad theme:
More details and detailed planning will be released at a later date. We welcome oral contributions and posters during the 3 thematic days.
Participation is free, but registration is mandatory. If you cannot make it, please unregister.
Confirmed speakers:
J. ABECASSIS, INRIA
J. BOBIN, CEA
L. CANTINI, Institut Pasteur
O. COLLIOT, Institut du Cerveau
D. CORNU, Observatoire de Paris
D. GRATADOUR, Observatoire de Paris
G. LEMAITRE, INRIA
J. LE SOMMER, UGA
B. LOUREIRO, ENS Paris
D. MARKOVIC, CNRS-Thalès
R. MENEGAUX, INRIA
N. NADERI, UP Saclay
C. PALLIER, INSERM-CEA
R. PLOUGONVEN , X
L. REINING, X
B. THIRION, INRIA
F. TUPIN, Télécom
Organisers:
With the generous help of Delphine Bueno, Marine Saux, toute l'équipe gestion du CMAP.
Picture credit: © Ecole polytechnique / Institut Polytechnique de Paris / Jérémy Barande
